Detecting deepfakes: what the evidence really shows
Yes, deepfakes can be detected. But the honest version of that answer comes with conditions. There is no single tell-tale sign, and unaided human eyes are barely better than guessing. How reliably a fake gets caught depends on two things: who is doing the judging, and whether the media is audio, an image, or video. The rest of this piece puts measured numbers on each of those, drawn from a peer-reviewed meta-analysis and a University of Florida study.
The short answer: yes, but not reliably by eye
A confident eyeball check is the wrong tool. High-end deepfakes are almost always facial transformations, so the face is where manual inspection starts, but no lone artifact confirms a fake on its own. The MIT Media Lab Detect Fakes project frames it plainly: you have to check multiple subtle clues together, because any one of them can be absent in a good fake and present in a real clip.
So detection is possible. What shifts is its reliability, and that hinges on the judge and the medium. A trained forensic pipeline reads a still image very differently from how a person skims a talking-head video. Keep that split in mind. It explains almost every surprising number that follows.
What the research actually measured: human detection accuracy
When researchers pooled the literature, the picture got uncomfortable. A systematic review and meta-analysis on ScienceDirect combined 56 papers covering 86,155 participants and found overall human detection accuracy of 55.54%. The 95% confidence interval ran from 48.87% to 62.10%. Because that range dips below 50%, the result is not statistically above chance. People, on average, are guessing with a slight edge.
Worse, the errors lean in one direction. People are biased toward judging a deepfake as authentic, and they overestimate how good they are at spotting fakes. A separate pre-registered experiment found participants could not reliably detect deepfakes yet believed they could, and neither awareness nor cash incentives moved the needle. Confidence and accuracy, it turns out, are nearly unrelated here.

Why detection rates differ by modality (audio vs image vs video)
Detectability is not one figure. The same meta-analysis broke human accuracy down by medium, and the spread is meaningful: audio came in highest at 62.08%, video sat at 57.31%, and still images landed lowest at 53.16%. Read that last number again. On photos, people are essentially flipping a coin.
| Modality | Human detection accuracy |
|---|---|
| Audio | 62.08% |
| Video | 57.31% |
| Image | 53.16% |
Why the gap? Deepfake video with audio is the hardest combination to catch. Viewers lock onto the message and follow the main idea, so small inconsistencies in lip sync or skin texture slip past unnoticed. Attention is a finite budget, and a coherent story spends it. The forensic researchers at West Oahu make the same point: the richer the clip, the more cover it gives the forgery.
Audio cuts the other way for the attacker. Voice cloning is cheap and fast. ZeroFox reports that a single 3-5 second sample is enough to clone a voice with about 85% accuracy, which is precisely why a phone call asking you to wire money is no longer a trustworthy channel. The voice on the line can be manufactured in seconds.
Human vs AI: who detects better, and when
Here is the counterintuitive part. The University of Florida studied automated detectors against people and found the advantage flips depending on the medium. On deepfake still faces, AI programs reached up to 97% accuracy, far beyond any human. Put the same person in a video and those same classifiers dropped to chance. Humans, meanwhile, correctly judged real versus fake videos about two-thirds of the time, outperforming the machines on exactly the format where the machines fail.
The reason sits in what each judge is good at. Automated tools feast on static, pixel-level artifacts frozen in a single frame, the kind of GAN fingerprint a still image preserves. Video adds temporal complexity: motion, micro-expressions, the way a head turns. People read that behavioral layer intuitively; current detectors lose the thread across frames.
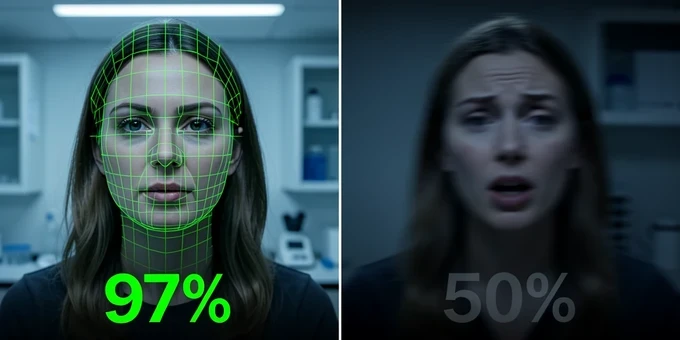
That gives you a working rule. Lean on automated tools when you are judging a still image. Stay skeptical of any single verdict on video, whether it comes from a person or a program. Neither judge is reliable alone across both formats.
What makes detection work: combining methods
Reliable detection is layered, not a single trick. The strongest approach stacks visual inspection, metadata analysis, forensic analysis, and machine learning, so a fake that survives one layer gets caught by another. No single pass is trusted to settle the question.
On the manual side, anatomy still betrays generators. AI struggles to render hands, ears, teeth, elbows, and toes, so those hard-to-model areas are worth a close look when you inspect a frame by eye. A sixth finger or a smear where teeth should be is a cheap, fast signal.
And humans can be improved, which is the encouraging finding buried in the data. Feedback training, AI support during the judgment, and caricaturization (exaggerating the manipulated features) lifted human accuracy to 65.14%, this time genuinely above chance. The jump from roughly 55% unaided to 65% assisted is real. It is also a reminder of how far raw intuition falls short before the help arrives.
Above-chance is not the same as dependable. Even a trained 65% rate misses about one in three, so assisted detection lowers the odds of being fooled without ever removing them.
The limits: an arms race and the rising stakes
Every accuracy figure here carries an expiry date. Generation keeps improving, so today's reliable cue becomes tomorrow's defeated one, and detection stays a moving target rather than a solved problem. There is a timing trap too: by the time a clip is analyzed, the fraud or the misinformation may already have done its work.
Real-time synthesis sharpens that trap. Proofpoint notes that modern tools generate synthetic faces and voices live, dropping a fabricated identity straight into a video call with no pre-recorded file to examine afterward. Post-analysis has nothing to analyze in the moment. The same source flags a second blind spot: standard authentication controls, including voice verification and video ID checks, cannot inherently tell a synthetic identity from a real one. The gate was never built for this.
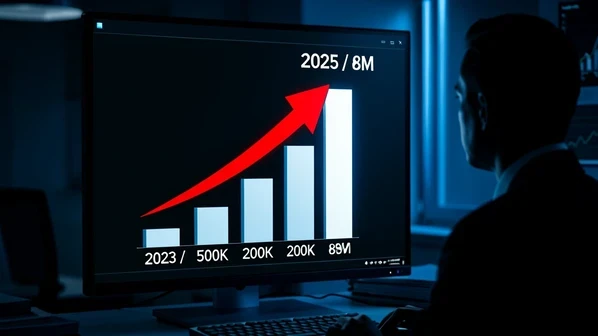
And the volume is scaling fast. The count of deepfake files online grew from roughly 500,000 in 2023 to an estimated 8 million in 2025. The financial damage tracked it: U.S. deepfake fraud losses topped $1.1 billion in 2025, more than triple the $360 million lost the year before.
The defense side is younger than the threat. A UK Government review of deepfake detection technology describes the market as nascent, with most providers focused on detecting fakes rather than preventing them. That gap matters: detection answers "was this real?" after the fact, while the harm often happens during. Until prevention catches up, the practical stance is calibrated suspicion, sized to the modality and to whoever, or whatever, is doing the judging.